
In diesem Artikel werden „Generational ZGC“ (JEP 439), „Key Encapsulation Mechanism API“ (JEP 452) und „Code Snippets in Java Doc“ (JEP 413) vorgestellt. Beim ersten JEP handelt es sich um eine kleine Anpassung an den neuem Z Garbage Collector, der einen riesigen Performance Boost auf jeder Größe von Heap verspricht. Beim zweiten geht es um ein neues API mit dem Schlüssel für eine besonders sichere symmetrische Verschlüsselung, die mit Public/Private-Key-Methoden übertragen werden kann, und im letzten um die Einbindung von Codebeispielen in der Java-API-Dokumentation.
JEP 439: Generational ZGC
Eine Instanz auf dem Heap kann entfernt werden, wenn sie nicht mehr benötigt wird. In hardwarenahen Sprachen sind die Entwicklerinnen und Entwickler dafür zuständig, den korrekten, sicheren Zeitpunkt zu bestimmen. Der sichere Zeitpunkt ist der, wenn keine andere Instanz mehr eine Referenz auf die Instanz gespeichert hat. Durch Call-by-Reference-Aufrufe von Methoden können sich diese Referenzen sehr weit im System verbreiten und die Analyse wird komplex. Die manuelle Bestimmung des Zeitpunkts der sicheren Entfernung ist sehr fehleranfällig und deswegen setzt die JVM, wie viele moderne Ökosysteme, auf das Konzept des Garbage Collector, kurz GC. Ein Garbage Collector überwacht dabei automatisiert den Speicher und entfernt Instanzen nach dem sicheren Zeitpunkt.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Hidden Heroes
Hidden Heroes leitet der Autor von dem Begriff „Hidden Champions“ ab, der von Hermann Simon geprägt wurde. Hidden Champions bezeichnen kleine Firmen, die Weltmarktführer sind und wenig Wahrnehmung in der Öffentlichkeit haben. Analog dazu sind Hidden Heroes Java-Features, die große Auswirkungen auf das JDK-Environment haben, aber gefühlt zu wenig Aufmerksamkeit in der Community bekommen.
In der Java Virtual Machine gibt es seit längerem mehrere verschieden implementierte Garbage Collectors mit diversen Schwerpunkten. Sie alle haben die GC-Pause gemein, in der die Anwendung pausiert werden muss:
- Serial GC ist der einfachste GC. Er benutzt nur einen Thread und pausiert die Applikation, während er läuft. Er ist für Einzelkernsysteme und nicht für Hardware mit mehreren Kernen geeignet, da kein Nutzen aus mehreren Rechenkernen gezogen werden kann.
- Parallel GC[1] verhält sich wie Serial GC, verwendet aber mehrere Kerne und ist damit eine bessere Alternative für Anwendungen auf Mehrkernhardware. Wie auch bei Serial GC ist die Länge der GC-Pause primär abhängig von der Größe des Heap-Speichers.
- G1 GC heißt eigentlich Garbage First GC [2] und wendet Partitionen auf dem Heap an. Die Partitionen werden entsprechend dem freien Speicher aufsteigend priorisiert und analysiert. G1 GC analysiert und entfernt Instanzen, bis die konfigurierte fixe Länge der GC-Pause verstrichen ist. Es werden oft nicht alle Partitionen komplett bearbeitet, denn das Ziel von G1 ist eine möglichst feste Pausenzeit. Zudem eignet er sich gut für Maschinen mit vielen Prozessoren und großen Heaps.
Relativ neu ist der Z Garbage Collector [3], der in Java 15 eingeführt wurde, kurz ZGC genannt. Der ZGC führt die arbeitsintensive Analyse des Heap parallel zur Ausführung der Anwendung in eigenen Threads durch. Dadurch muss die Anwendung nur sehr kurz unterbrochen werden, um die Threads zu synchronisieren. Die GC-Pause ist dabei 1 ms lang und unabhängig von der analysierten Heapgröße. Realisiert wird die Parallelität mit Hilfe von Colored Pointer und Load Barriers. Colored Pointer sind eine Dekoration eines Pointers, einer Speicheradresse mit Metainformationen über den Status der Instanz. Load Barriers werden für Zugriffe auf Referenzen eingebaut. Sie werten Colored Pointer aus und führen potenziell notwendige Weiterleitungen durch, bevor die Anwendung auf die Instanz zugreift, um Adressänderungen zu verschleiern. Der hochoptimierte Algorithmus von ZGC wird im Artikel „Deep-dive of ZGC’s Architecture“ [4] auf Dev.java ausführlich beschrieben und ist in der Lage, sehr kleine und sehr große Heaps bis 16 TB effizient zu bearbeiten. Aktiviert werden kann ZGC durch den Kommandozeilenparameter -XX:+UseZGC. Bei der ersten Verwendung von ZGC wird empfohlen, auch GC-Logging (-Xlog:gc) zu aktivieren, um das Finetuning der Konfiguration zu ermöglichen. Neben der Anzahl der von ZGC verwendeten Threads (-XX:ConcGCThreads) und einigen Linux-spezifischen Parametern kann auch das Zurückgeben von Speicher an das Betriebssystem aktiviert werden (-XX:+ZUncommit).
Mit JEP 439: Generational ZGC [5] wird ZGC um die Partitionierung des Heap in Generationen, also je einen Bereich für „jung“ und „alt“, erweitert. Der Bereich für die jungen Instanzen unterteilt sich noch in „Eden“ und „Survivor“. Neu erzeugte Instanzen werden in der Regel in Eden erzeugt und, wenn sie den ersten Durchlauf des GC „überleben“, nach Survivor kopiert. Nachdem sie eine feste Anzahl GC-Läufe in Survivor „überlebt“ haben, werden Instanzen in den Bereich für alte Instanzen kopiert. Die Partitionierung ermöglicht die Anwendung der Weak Generational Hypothesis [6], die im Kern aussagt: „Junge Instanzen haben die Tendenz, jung zu sterben“. Als Konsequenz kann unter Instanzen im Bereich „jung“ und besonders unter denen im Bereich Eden vermutet werden, dass sie nicht mehr referenziert werden und zu entfernen sind. Im Bereich „alt“ sind wahrscheinlich kaum zu entfernende Instanzen enthalten und diese werden nicht so häufig analysiert. Durch die getrennte Behandlung verringert sich der durchschnittliche Aufwand der Analyse und der GC-Prozess wird effizienter. Aktiviert werden kann diese Partitionierung mit dem Parameter -XX:+ZGenerational. Zukünftig soll ZGC nur noch den Ansatz mit Generationen verwenden, dann ist der Parameter nicht mehr notwendig.
Mit seiner effizienten Behandlung von riesigen Heaps, der geringen GC-Pause und dem Fokus auf das Entfernen von jungen Instanzen ist Genrational ZGC optimiert für datenintensive Anwendungen, die eine kurze Antwortzeit erfordern. Damit kann Generational ZGC eine gute Wahl für moderne datengetriebene Systeme im Enterprise-Umfeld sein. Durch die hohe Komplexität und viel notwendiger Theorie in diesem Themenfeld fehlt es Generational ZGC ein wenig an Aufmerksamkeit, deswegen ist Generational ZGC ein Hidden Hero des Java-Ökosystems.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
JEP 452: Key Encapsulation Mechanism API
In der elektronischen Kommunikation wird an vielen Stellen auf Verschlüsselung gesetzt. Viele der heute gängigen Verfahren gelten als nicht sicher für ein Zeitalter mit Quantencomputern. An einem solchen Quantencomputer könnte zum Beispiel Mallroy forschen – und vor kurzen hatte er einen großen Durchbruch. Alice und Bob wollen deswegen eine Überraschungsparty für ihren Freund Mallroy organisieren. Damit Mallroy unwissend bleibt, wollen Alice und Bob nur über sichere, verschlüsselte Kanäle miteinander kommunizieren. Sie wollen zahlreiche Nachrichten austauschen und Mallroy könnte schon den Quantencomputer zur Verfügung haben, deswegen kommt nur ein effizientes und hochsicheres Verfahren in Frage.
Bei ihrer Recherche erfahren sie, dass es symmetrische und asymmetrische Verfahren gibt. Bei einem asymmetrischen Verschlüsselungsverfahren werden zwei verschiedene Schlüssel zum Ver- und Entschlüsseln verwendet. Der Schlüssel zum Verschlüsseln kann gefahrenlos übermittelt werden, leider sind diese Algorithmen in der Regel nicht hochperformant und auch nicht besonders sicher. Bei symmetrischen Verfahren wird derselbe Schlüssel zum Ver- und Entschlüsseln verwendet, sie punkten bei Effizienz und Sicherheit ganz klar. Leider benötigen beide Seiten das Wissen über den verwendeten Schlüssel und dieser kann, da geheim, nicht trivial versendet werden.
Im 2001 von Cramer und Shoup veröffentlichten Artikel „Design and Analysis of Practical Public-Key Encryption Schemes Secure against Adaptive Chosen Ciphertext Attack“ [7] wird in § 7.1 der Mechanismus „Key Encapsulation“ beschrieben, mit dem es möglich ist, Schlüssel für symmetrische Verschlüsselungsverfahren unter Zuhilfenahme asymmetrischer Verschlüsselung sicher zu übertragen. Dieses unter der Abkürzung KEM bekannte Verfahren wird unter anderem vom BSI und der NIST in ihren Post-Quanten-Kryptografie-Konzepten als Basisbaustein betrachtet [8], [9]. In Abbildung 1 ist der KEM-Ablauf zwischen Alice und Bob dargestellt. Zuerst generiert Alice ein Schlüsselpaar aus öffentlichem und privatem Schlüssel. Der öffentliche Schlüssel wird an Bob übertragen. An dieser Stelle ist eine Transportverschlüsselung zwischen Alice und Bob wichtig, aber nicht Gegenstand des Verfahrens. Bob erzeugt einen zufälligen Schlüssel für das später verwendete symmetrische Verschlüsselungsverfahren und verschlüsselt diesen mit dem öffentlichen Schlüssel von Alice. Dieses als „Encupsulated“ bekannte Datenpaket wird an Alice zurückübertragen, und nur sie kann es mit ihrem privaten Schlüssel entschlüsseln. Von nun an können Alice und Bob ihre Nachrichten mit einer symmetrischen Verschlüsselung austauschen, das Schlüsselpaar wird nicht mehr gebraucht.
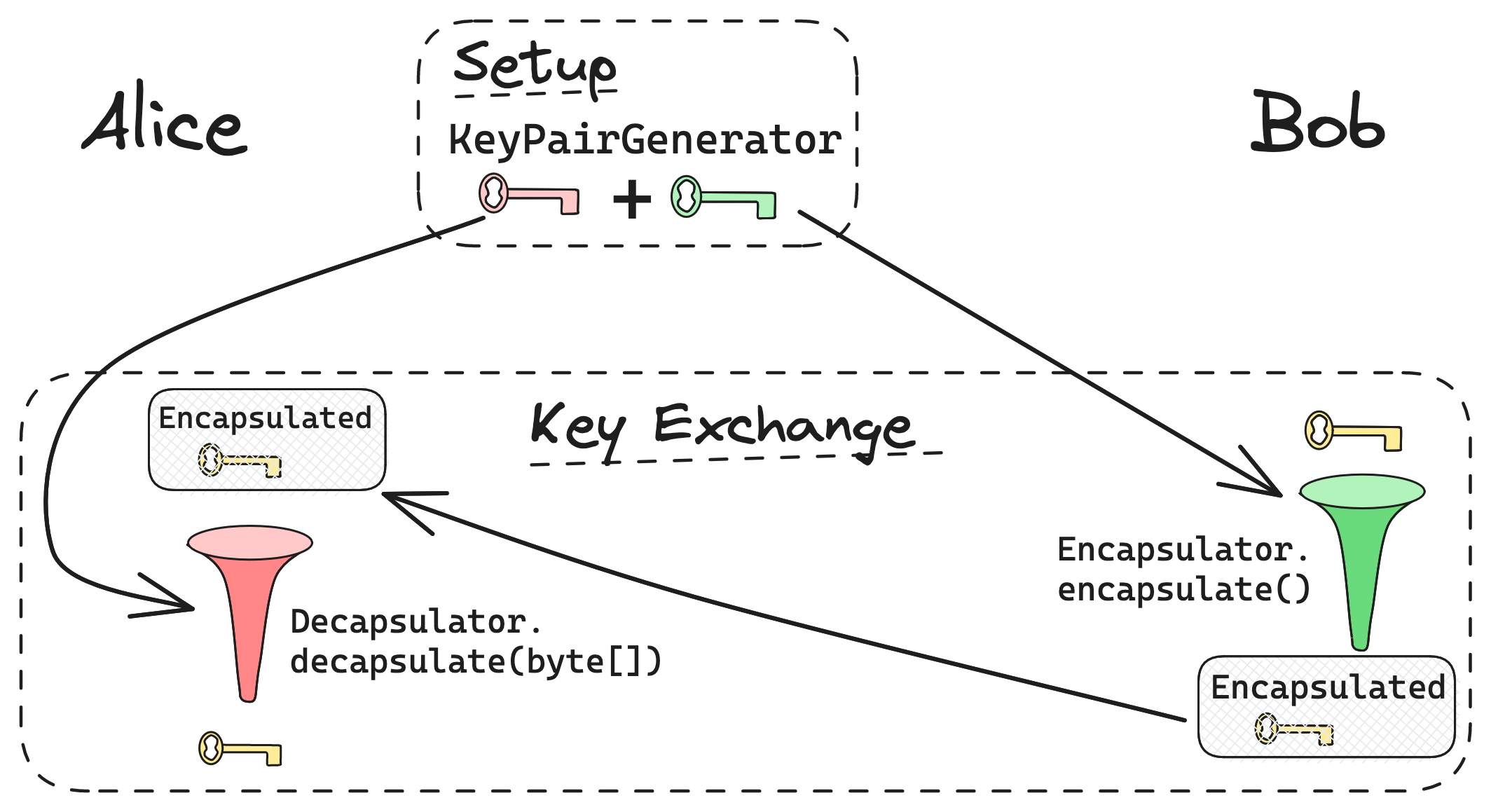
Abb. 1: Bob und Alice tauschen den Schlüssel für eine symmetrische Verschlüsselung (gelb) mit KEM aus
Da die Implementierung sicherheitsrelevanter Features und insbesondere von Verschlüsselungen ein hochkomplexes Feld ist, gleichzeitig aber die Verschlüsselung eine grundlegende Anforderung moderner Systeme ist, wird mit JEP 452 [10] ein API zur Durchführung eines KEM-Prozesses in Java 21 eingeführt. Das API folgt dem von der ISO 18033-2 definierten und oben beschriebenen Prozess. Dabei bilden drei Bausteine das Fundament für eine sichere Verschlüsselung. Der javax.crypto.KEM.Encapsulator verwendet den öffentlichen Schlüssel und den erzeugten symmetrischen Schlüssel, um ein Encapsulated zu erzeugen. Das Encapsulated wird durch eine Instance von javax.crypto.KEM.Encapsulated repräsentiert und kann direkt als Bytearray von Bob übertragen werden. Auf Alices Seite wird die Klasse javax.crypto.KEM.Decapsulator verwendet, um mit dem passenden privaten Schlüssel den symmetrischen Schlüssel zu erlangen.
Im nun folgenden Beispiel bilden die Methoden sendToBob/sendToAlice und retrieveFromBob/ retrieveFromAlice die jeweilig sendenden beziehungsweise empfangenden Enden der unsicheren Kommunikationskanäle zwischen Alice und Bob ab. Listing 1 zeigt, wie das Set-up des KEM-Prozesses bei Alice mit dem KeyPairGenerator implementiert wird. Die Methode KeyPairGenerator#getInstance(String) erzeugt einen Schlüsselpaarerzeuger für das RSA-Verfahren. Über ein Service Provider Interface ist es möglich, hier weitere Algorithmen zu hinterlegen. Mit dem Aufruf von KeyPairGenerator#generateKeyPair() wird ein Paar aus öffentlichem und privatem Schlüssel erzeugt. Dieses Paar wird bei Alice hinterlegt und der öffentliche Schlüssel an Bob versandt.
var keyGen = KeyPairGenerator.getInstance("RSA");
var pair = keyGen.generateKeyPair();
sendToBob(pair.getPublic());
In Listing 2 wird die erste Phase der Key Exchanges auf der Seite von Bob gezeigt. Nachdem der öffentliche Schlüssel von Alice empfangen wurde, wird mir KEM#getInstance(String) eine für RSA konfigurierte Implementierung gewählt. Neue Implementierungen können auch hier durch ein SPI bereitgestellt werden. Auf der konkreten KEM-RSA-Instanz wird mit der Methode KEM#newEncapsulator(java.security.PublicKey) eine Encapsulator-Instanz für RSA-KEM erzeugt. Der zufällig erzeugte Schlüssel kann und sollte über Encapsulated#key() abgerufen und bei Bob hinterlegt werden (hier in der Variable secret). Mit diesem Schlüssel wird die spätere symmetrische Verschlüsselung durchgeführt. Auf das zu versendende Encapsulate kann über die Methode Encapsulated#encapsulate() zugegriffen werden und es wird von Bob an Alice versendet.
var publicKey = retrieveFromAlice();
var encapsulator = KEM.getInstance("RSA-KEM").newEncapsulator(publicKey);
var secret = encapsulate.key();
var encapsulate = encapsulator.encapsulate();
sendToAlice(encapsulate.encapsulation());
In Listing 3 wird die zweite Phase der Key Encapsulation bei Alice gezeigt. Nachdem das Encapsulate von Bob empfangen und der private Schlüssel aus dem Schlüsselpaar des Set-ups entnommen wurde, kann mit dem Entpacken des symmetrischen Schlüssels begonnen werden. Zuerst wird wieder mit der Methode KEM#getInstance(String) die konkrete Implementierung von KEM für RSA-KEM geladen. Mit dem Aufruf KEM# newDecapsulator(PrivateKey) wird unter Zuhilfenahme des privaten Schlüssels der symmetrische Schlüssel entpackt.
byte[] encapsulate = retrieveFromBob();
var privateKey = pair.getPrivate();
var decapsulator = KEM.getInstance("RSA-KEM").newDecapsulator(privateKey);
var secret = decapsulator.decapsulate(encapsulate);
Von diesem Moment an ist das verwendete öffentliche und private Schlüsselpaar nicht mehr notwendig und kann gelöscht werden. Die Kommunikation kann nun sicher und effizient mit einem symmetrischen Verschlüsselungsverfahren durchgeführt werden. Mit diesem sehr neuen Feature in Java 21 rüstet die OpenJDK-Community das Ökosystem Java für das Post-Quantum-Zeitalter auf. Die Verwendung von Java in einer Welt voller Quantencomputer ist nun möglich und aus diesem Grund sollte dieses Feature mehr Aufmerksamkeit bekommen. Es ist auf jeden Fall ein Hidden Hero von Java 21.
JEP 413: Code Snippets in Java API Documentation
An Schnittstellen stellen Entwickler und Entwicklerinnen ganz eigene Anforderungen. Oft sind Benutzbarkeit und verständliche Dokumentation die wichtigsten Aspekte. Aus diesem Grund ist Javadoc als Dokumentationswerkzeug für Source Code bereits seit Java 1 Teil des JDK. Mit Javadoc können Kommentare mit beschreibenden Tags angereichert werden und in eine navigierbare und durchsuchbare Schnittstellendokumentation überführt werden. Neben Beschreibungen der Parameter und des Verhaltens ist es sinnvoll, die beabsichtigte Verwendung zu dokumentieren, um die Hürden der Einarbeitung zu verringern. Es haben sich einige unterschiedliche Ansätze etabliert:
- Separate Tutorials wie die Referenzdokumentation von Spring [11] oder Extensions Guides von Quarkus [12]. Hier liegt der Fokus eher auf der Verwendung des Frameworks und weniger auf dem API.
- Bei Code Snippets als HTML mit <pre>{@code } </pre> liegt das API im Fokus. Das Snippet wird leider nicht ansehnlich formatiert und muss bei jeder Änderung an der Schnittstelle bedacht werden. Ein Beispiel ist java.util.stream.Stream [13], [14].
- Unit Tests als Dokumentation zu betrachten, ist ein guter Ansatz, vorausgesetzt die Tests sind gut und die verwendenden Entwickler und Entwicklerinnen haben Zugriff auf den Code. Bedauerlicherweise fehlt bei diesem Ansatz oft die Verknüpfung zwischen Code und Tests.
Mit JEP 413: Code Snippets in der Java-API-Dokumentation [15] hält Java seit Version 18 eine Möglichkeit bereit, Source-Code-Auszüge mit Syntax-Highlighting und Testbarkeit zu vereinen, um Entwicklerinnen und Entwicklern das Einbinden von guten Beispielen in der API-Dokumentation zu ermöglichen. Um ein Snippet in einem Javadoc-Kommentar einzubinden, wird der neue {@snippet: … }-Tag verwendet.
/**
* Berechnung der MwSt für einen Privatkunden beim Einkauf in Höhe von 1055
* {@snippet :
* var kunde = new Privatkunde("Merlin", "");
* var wert = 1055d;
* // ...
* var mwst = MwStRechner.PlainOOP.calculateMwSt(kunde, wert);
* }
*/
In Listing 4 wird in einem Inline Snippet die erwartete Interaktion mit dem API des MwStRechner aus dem Data-Oriented-Programming-Beispielprojekt des Autors [16] dargestellt. In der generierten Dokumentation ist der Bereich ab der neuen Zeile hinter dem Doppelpunkt bis zur letzten Zeile vor der schließenden Klammer als formatierter Source Code mit Syntax-Highlighting enthalten. Bei Inline Snippets gibt es zwei Randbedingungen:
- Ein mehrzeiliger Kommentar mit /* */ ist nicht erlaubt.
- Für jede geöffnete Klammer muss auch eine schließende enthalten sein.
Ohne diese Randbedingungen ist es dem Generator nicht möglich, die Passage korrekt zu konvertieren. Zusätzlich muss die syntaktische Korrektheit manuell geprüft und Schnittstellenänderungen beachtet werden. Für ein externes Snippet gelten diese Rahmenbedingungen allesamt nicht. Bei einem externen Snippet wird der Inhalt nicht im selben Kommentar angegeben, sondern aus einer vorhandenen Java-Datei entnommen.
/**
* Berechnung der MwSt für einen Privatkunden beim Einkauf in Höhe von 1055
* {@snippet file="SwitchExpressionsSnippets.java" region="example"}
*/
// Datei: snippet-files/Snippets.java
class Snippets {
public void snippet01() {
void snippet01() {
// @start region="example"
// @replace region="replace" regex='(= new.*;)|(= [0-9]*d;)' replacement="= ..."
// @highlight region="highlight" regex="\bMwStRechner\b"
var kunde = new Privatkunde("Merlin", "[email protected]"); // @replace regex="var" replacement="Kunde"
var wert = 1055d; // @replace regex="var" replacement="double"
/* .. */
var mwst = MwStRechner.PlainOOP.calculateMwSt(kunde, wert); // @link substring="PlainOOP.calculateMwSt" target="MwStRechner.PlainOOP#calculateMwSt"
// @end @end @end
}
}
In Listing 5 wird ein externes Snippet verwendet, das auf eine Datei Snippets.java (auch Listing 5) im Ordner snippet-files verweist. Dieser Ordner liegt direkt neben der Datei, in der das Snippet eingebunden wird und kann mit Hilfe der Konfiguration -snippet-path überschrieben werden. Den Pfad auf den Ordner mit dem Test zu konfigurieren, erscheint dem Autor als guter Standard. Dadurch ist es möglich, die geschriebenen Tests als Beispiele wiederzuverwenden. In Listing 2 ist zudem eine Region definiert. Dadurch werden nur bestimmte Bereiche der referenzierten Java-Datei verwendet und die Datei kann so Beispiele für verschiedene Anwendungsfälle enthalten.
Stay tuned
Regelmäßig News zur Konferenz und der JAX-Community erhalten
Neben Bereichen sind in dem Snippet in Listing 5 noch weitere Anpassungen durchgeführt worden. Mit den @replace Tags werden per regulärem Ausdruck zuerst alle Initialisierungen durch … ersetzt, da sie nicht direkt zum Beispiel beitragen. Das Schlüsselwort var wird in den entsprechenden Zeilen durch den Datentyp ersetzt. Hierbei wird keine Region angeben, also die Ersetzung nur auf diese Zeile angewandt. Mit dem Tag @highlight wird jedes Vorkommen von MwStRechner hervorgehoben und mit @link ein Link zur Methode MwStRechner.PlainOOP#calculateMwSt erstellt. In Abbildung 2 wird das Ergebnis der Javadoc-Generierung des Listings 5 gezeigt.
Abb. 2: Aus Listing 5 generierte Dokumentation mit Ersetzungen, Links und Highlights
Durch die Möglichkeit zur Verknüpfung zwischen Source Code und API-Dokumentation kann gewährleistet werden, dass auch Listings in Javadoc aktuell und von hoher Qualität sind. Die Dokumentation von APIs gewinnt dadurch an Qualität, Aktualität und einem hohen Grad an Verständlichkeit. Werden alle Tags in einem Snippet verwendet, wird das Lesen des zugrundeliegenden Codes erschwert. Das betrifft vor allem die Entwicklerinnen und Entwickler von Frameworks und Tools. Von ihrem Mehraufwand werden aber alle profitieren, deswegen sind Code Snippets in Java API Documentation auf jeden Fall ein Hidden Hero im Java-21-Ökosystem.
Zusammenfassung
In diesem Artikel wurden drei der vielen Hidden Heroes im JDK-Ökosystem abseits von Virtual Threads und Pattern Matching gezeigt. Es gibt noch einige mehr, wie beispielsweise Class Data Sharing und den Simple Web Server, aber das ist Material für einen weiteren Beitrag auf Konferenzen, User Groups oder für das Selbststudium.
Links & Literatur
[1] https://docs.oracle.com/en/java/javase/20/gctuning/parallel-collector1.html
[2] https://docs.oracle.com/en/java/javase/20/gctuning/garbage-first-garbage-collector-tuning.html
[3] https://docs.oracle.com/en/java/javase/20/gctuning/z-garbage-collector.html
[4] https://dev.java/learn/jvm/tool/garbage-collection/zgc-deepdive/
[5] https://openjdk.org/jeps/439
[6] https://docs.oracle.com/en/java/javase/17/gctuning/garbage-collector-implementation.html
[7] Design and Analysis of Practical Public-Key Encryption Schemes Secure against Adaptive Chosen Ciphertext Attack, Crammer und Shoup 2001, https://eprint.iacr.org/2001/108.pdf
[8] https://www.bsi.bund.de/DE/Themen/Unternehmen-und-Organisationen/Informationen-und-Empfehlungen/Quantentechnologien-und-Post-Quanten-Kryptografie/Post-Quanten-Kryptografie/post-quanten-kryptografie_node.html
[9] https://csrc.nist.gov/News/2022/pqc-candidates-to-be-standardized-and-round-4
[10] https://openjdk.org/jeps/452
[11] https://docs.spring.io/spring-data/jpa/docs/current/reference/html/
[12] https://quarkus.io/guides/resteasy-reactive
[13] https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/stream/Stream.html
[14] https://github.com/openjdk/jdk/blob/4de3a6be9e60b9676f2199cd18eadb54a9d6e3fe/src/java.base/share/classes/java/util/stream/Stream.java#L52-L57
[15] https://openjdk.org/jeps/413
[16] https://github.com/MBoegers/DataOrientedJava




